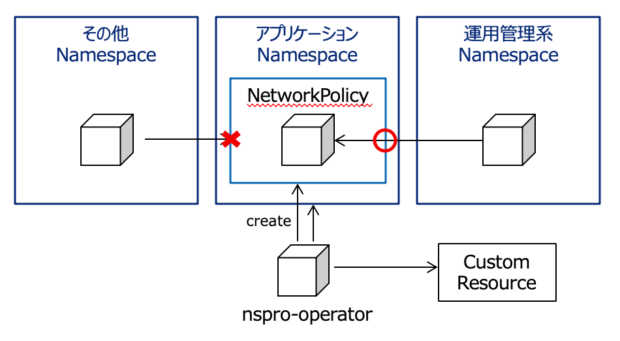
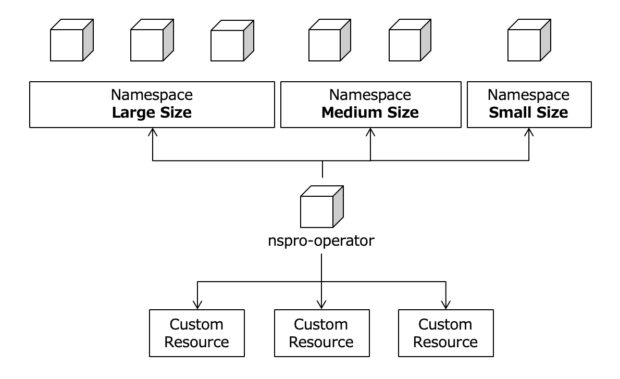
NamespaceをプロビジョニングするOperatorがあったら、マルチテナントでクラスター運用するのが楽になるかなぁと思い、Operatorを作成しています。本日はNamespaceにおけるユーザーアクセス権限のプロビジョニング機能を作成します。
- はじめに
- Operatorを作成する
- Operatorをビルドする
- Operatorをデプロイする
- Operatorを確認する
- ユーザーを作成する
- Contextを作成する
- CRを作成する
- 権限を確認する
はじめに
最近、NamespaceをプロビジョニングするOperatorを作成しています。以下の関連記事にあるように、これまでResourceQuotaやNetworkPolicyをプロビジョニングするOperatorを作成しました。
本記事では、このOperatorにアクセス権限をプロビジョニングする機能を追加します。具体的には、CR(Cutom Resouce)に指定されたGroupに所属するユーザーが、Namespaceにアクセスできるように設定します。システムやプロジェクト単位でNamespaceを分割する際、関係ないユーザーが勝手に操作することを防げるので、必ずと言っていいほどインフラチームが実施する設定です。
Operatorを作成する
CRDを作成する
CRで設定できる設定項目を定義します。今回は、pkg/apis/nspro/v1alpha1/nspro_types.goのNsproSpecにAllowedGroup []string `json:”allowedGroup”`を加えて、Namespaceにアクセス可能なグループを指定できるようにします。
Operator SDKのインストール方法は、Operator SDK をインストールしてOperatorを作成する(1/2)で紹介していますので、よろしければご参照ください。
type NsproSpec struct {
// INSERT ADDITIONAL SPEC FIELDS - desired state of cluster
// Important: Run "operator-sdk generate k8s" to regenerate code after modifying this file
// Add custom validation using kubebuilder tags: https://book.kubebuilder.io/beyond_basics/generating_crd.html
NsSize string `json:"nssize"`
Managed bool `json:"managed"`
AllowedGroup []string `json:"allowedGroup"`
}
変更を加えたら、以下のコマンドで必要なコードを再生成します。
$ operator-sdk generate k8s
INFO[0006] Running deepcopy code-generation for Custom Resource group versions: [nspro:[v1alpha1], ]
INFO[0011] Code-generation complete.
Controllerを追加する
ControllerのReconcile関数には、newRolePolicyForNSとnewRoleBindingForNSを呼び出してRole, RoleBindingリソースを作成する処理を記述します。
func (r *ReconcileNspro) Reconcile(request reconcile.Request) (reconcile.Result, error) {
~~省略~~
role := r.newRoleForNS(instance)
err = r.client.Create(context.TODO(), role)
group_names := instance.Spec.AllowedGroup
for i := range group_names {
rb := r.newRoleBindingForNS(instance, group_names[i])
err = r.client.Create(context.TODO(), rb)
}
~~省略~~
}
newRoleforNSは以下の通りで、CRで作成するNamespaceの全権限(クラスター権限を除く)を付与します。作成方法は他のリソースと同じですが、RoleとRoleBindingの定義は、vender/k8s.io/api/rbac/v1/type.goに記述されています。
func (r *ReconcileNspro) newRoleForNS(cr *nsprov1alpha1.Nspro) *rbacv1.Role {
nsname := cr.Name
role := &rbacv1.Role {
ObjectMeta: metav1.ObjectMeta {
Name: nsname + "-role",
Namespace: nsname,
},
Rules: []rbacv1.PolicyRule {
{
APIGroups: []string{ rbacv1.APIGroupAll },
Resources: []string{ rbacv1.ResourceAll },
Verbs: []string{ rbacv1.VerbAll },
},
},
}
controllerutil.SetControllerReference(cr, role, r.scheme)
return role
}
newRoleBindingForNSは以下の通りで、newRoleforNSで作成したRoleをCRに指定されたGroupに付与します。
func (r *ReconcileNspro) newRoleBindingForNS(cr *nsprov1alpha1.Nspro, group_name string) *rbacv1.RoleBinding {
nsname := cr.Name
rb := &rbacv1.RoleBinding {
ObjectMeta: metav1.ObjectMeta {
Name: nsname + "-rb",
Namespace: nsname,
},
Subjects: []rbacv1.Subject {
{
Kind: "Group",
Name: group_name,
APIGroup: "rbac.authorization.k8s.io",
},
},
RoleRef: rbacv1.RoleRef {
Name: nsname + "-role",
Kind: "Role",
APIGroup: "rbac.authorization.k8s.io",
},
}
controllerutil.SetControllerReference(cr, rb, r.scheme)
return rb
}
Operatorをビルドする
作成したOperatorのコンテナイメージをビルドします。
$ operator-sdk build 192.168.64.2:32000/nspro-operator:v1
以下のコマンドでレジストリに登録します。今回はMicroK8s上のコンテナレジストリ上に登録するので、[WorkerNodeのIPアドレス]:[NodePort]/[イメージ名]:[タグ名]のように登録しておきます。
$ docker push 192.168.64.2:32000/nspro-operator:v1
Operatorをデプロイする
Operatorをデプロイします。Operatorの前にCRDを作成しないとapiVersionが利用できないので、CRDから作成します。
$ kubectl create -f deploy/crds/nspro_v1alpha1_nspro_crd.yaml
customresourcedefinition.apiextensions.k8s.io/nspros.nspro.example.com created
続いてdeploy/配下にあるyamlを作成します。operator.yamlだけイメージ名を変更する必要があります。
$ kubectl delete -f deploy/operator.yaml
deployment.apps "nspro-operator" deleted
$ kubectl create -f deploy/operator.yaml -n nspro-operator
deployment.apps/nspro-operator created
$ kubectl create -f deploy/service_account.yaml -n nspro-operator
serviceaccount/nspro-operator created
$ kubectl create -f deploy/role.yaml -n nspro-operator
role.rbac.authorization.k8s.io/nspro-operator created
$ kubectl create -f deploy/role_binding.yaml -n nspro-operator
rolebinding.rbac.authorization.k8s.io/nspro-operator created
デプロイすると以下のエラーが発生します。
E0701 15:06:25.610185 1 reflector.go:134] sigs.k8s.io/controller-runtime/pkg/cache/internal/informers_map.go:126: Failed to list *v1alpha1.Nspro: nspros.nspro.example.com is forbidden: User "system:serviceaccount:nspro-operator:nspro-operator" cannot list resource "nspros" in API group "nspro.example.com" in the namespace "nspro-operator"
アクセス権限を付与するために、以下の記事でRBAC機能を有効化したことによってOperatorに権限がなくなったことが原因です。
MicroK8sへのユーザー追加と権限付与でハマった話
従って、OperatorにCluster権限を与える必要があります。以下のyamlを使ってnspro-operator ServiceAccountにcluster-adminを付与します。
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: admin-for-nspro-operator
subjects:
- kind: ServiceAccount
name: nspro-operator
namespace: nspro-operator
roleRef:
kind: ClusterRole
name: cluster-admin
apiGroup: rbac.authorization.k8s.io
Operatorを確認する
CRを作成してOperatorの挙動を確認します。
ユーザーを作成する
Operator確認用に、dev1グループに所属するdev1-user01とdev2グループに所属するdev2-user01を作成します。
basic_auth.csv に以下の行を追加します。今回はMicroK8sを利用しているので/var/snap/microk8s/current/credentials/配下にあります。環境毎にパスが異なるので注意してください。
[dev1-user01のパスワード],dev1-user01,dev1-user01,"system:authenticated,developer,dev1"
[dev2-user01のパスワード],dev2-user01,dev2-user01,"system:authenticated,developer,dev2"
Contextを作成する
~/.kube/config を編集して、dev1-user01とdev2-user01で操作する用のContextを作成します。
apiVersion: v1
clusters:
- cluster:
insecure-skip-tls-verify: true
server: https://127.0.0.1:16443
name: microk8s-cluster
contexts:
- context:
cluster: microk8s-cluster
user: admin
name: microk8s
- context:
cluster: microk8s-cluster
user: dev1-user01
name: microk8s-dev1
- context:
cluster: microk8s-cluster
user: dev2-user01
name: microk8s-dev2
current-context: microk8s
kind: Config
preferences: {}
users:
- name: admin
user:
password: [adminのパスワード]
username: admin
- name: dev1-user01
user:
password: [dev1-user01のパスワード]
username: dev1-user01
- name: dev2-user01
user:
password: [dev2-user01のパスワード]
username: dev2-user01
CRを作成する
CRを作成してNamespaceをプロビジョニングします。
dev1グループがアクセスできるdev1-nsとdev2グループがアクセスできるdev2-nsを以下のyamlを使って作成します。
apiVersion: nspro.example.com/v1alpha1
kind: Nspro
metadata:
name: dev1-ns
spec:
nssize: large
managed: true
allowedGroup: ["dev1"]
apiVersion: nspro.example.com/v1alpha1
kind: Nspro
metadata:
name: dev2-ns
spec:
nssize: large
managed: true
allowedGroup: ["dev2"]
$ kubectl create -f deploy/crds/dev1-ns.yaml -n nspro-operator
nspro.nspro.example.com/dev1-ns created
$ kubectl create -f deploy/crds/dev2-ns.yaml -n nspro-operator
nspro.nspro.example.com/dev2-ns created
$ kubectl get ns dev1-ns dev2-ns
NAME STATUS AGE
dev1-ns Active 82s
dev2-ns Active 74s
権限を確認する
dev1-user01とdev2-user01のコンテキストに切り替えて、それぞれの権限を確認すると、以下のようにCRのallowedGroupに指定されたNamespaceのみアクセスできることがわかります。
$ kubectl config use-context microk8s-dev1
Switched to context "microk8s-dev1".
$ kubectl auth can-i get pods -n dev1-ns
yes
$ kubectl auth can-i get pods -n dev2-ns
no
$ kubectl config use-context microk8s-dev2
Switched to context "microk8s-dev2".
$ kubectl auth can-i get pods -n dev1-ns
no
$ kubectl auth can-i get pods -n dev2-ns
yes
以上です。段々Operatorの使い方も慣れてきました。